11 Overview
We are not done yet 😱! FLIM Playground also provides a suite of methods to analyze and visualize the extracted data (either using the Data Extraction section or in users’ own way). They are designed to be interactive and frictionless ⚡ so that users can perform hassle-free exploration of their data with, hopefully, fun 😎. Inspired by the same data categorization in Data Extraction, the Data Analysis section designs an architectural blueprint that all in-house analysis methods build on. It is modularized so that new methods and features can be added in the future easily.
11.1 General Workflow
- Select numerical feature(s) on the left.
- Subset the data to find data of interest on the top. All the later interactions are based on this filtered dataset.
- Use visual channels widgets to look at the data in different ways.
- Change the plot style.
- Hover to find data points of interest.
- Interact with method-specific widgets that typically are associated with a modeling method.
- Once users are satisfied with the analysis (visualizations and statistical modeling results), they can export the entire analysis workflow as a self-contained Python script! 🎉
The visualization and analysis results are updated in real time to reflect users’ interactions with any of the above widgets.
11.2 Methods
- Depending on the number of numerical features in the analysis, the methods are categorized into 3 groups:
- Univariate Analysis
- Bivariate Analysis
- Multivariate Analysis
All the methods share a set of interactive widgets. They also have their own method-specific widgets, the descriptions of which are provided in the corresponding method pages.



11.3 Input
Users can upload the dataset output from the Data Extraction directly or their own datasets in CSV (Comma Separated Values) format after finishing the interactive configuration setup.


11.3.1 Requirements
In either case, following the categorization, the dataset should have:
- a column that uniquely identifies each row
- an (optional) field of view identifier column
- a set of numerical features
- zero or more categorical features (e.g. treatment, day, patient id, etc.)
The unique row id and field of view id are used to help users identify the row (e.g. a single cell) and field of view (e.g. a single image) of data of interest through the built-in hover-based interaction. Numerical and categorical features are used to render shared widgets. Internally, FLIM Playground will check whether the dataset fulfills the requirements and output meaningful warning or error messages.
If you cannot find a certain numerical feature under any numerical widgets including Uncategorized Features, please inspect the dataset (e.g., using Excel filters) and look for non-numeric values in that column. One non-numeric value (e.g., “–”) will prevent it from being recognized.
FLIM Playground searches for categorical features in the uploaded dataset based on the user-specified configuration if the dataset is not extracted by Data Extraction. Otherwise, it searches for categorical features specified in the Data Extraction configuration.
11.3.2 Warning Messages
Empty columns: will be dropped.Duplicated columns: Only the first occurrence of the duplicated column will be kept. Other occurrences will be dropped.Duplicated rows based on the unique row id: Only the first occurrence of the duplicated row will be kept. Other occurrences will be dropped.Columns with NaN values: won’t be dropped, just a warning message.- The analysis will be performed on the rows that are not NaN in the selected numerical features.
11.3.3 Error Messages
- Missing a column that uniquely identifies each row
- Cannot identify any numerical feature column
- It uses
pd.api.types.is_numeric_dtypeto check if a column is numerical.
- It uses
Warning messages will not prevent the analysis but error messages will.
11.4 Shared Interactive Widgets
A list of shared widgets is provided to support the general workflow in analysis.
11.4.1 Numerical Selection Widgets
The Data Extraction recognizes numerical features using pd.api.types.is_numeric_dtype internally. Then it groups numerical features based on the feature extractor type and the channel it belongs to. For user-provided datasets, the numerical features are grouped based on the user-specified configuration. Ungrouped numerical features are put into the Uncategorized Features group. One selection widget is rendered for each numerical feature group.
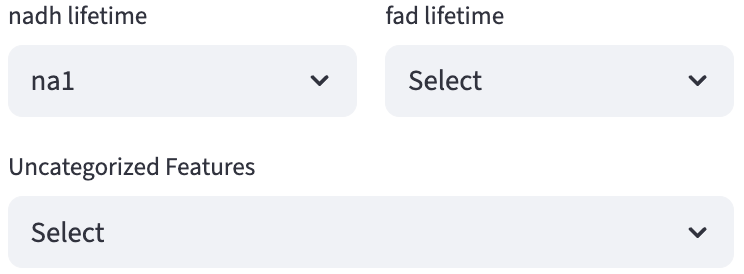
Univariate Analysis
One single-select widget is rendered per group; choosing a feature in any group clears the selections and resets the others to Select.
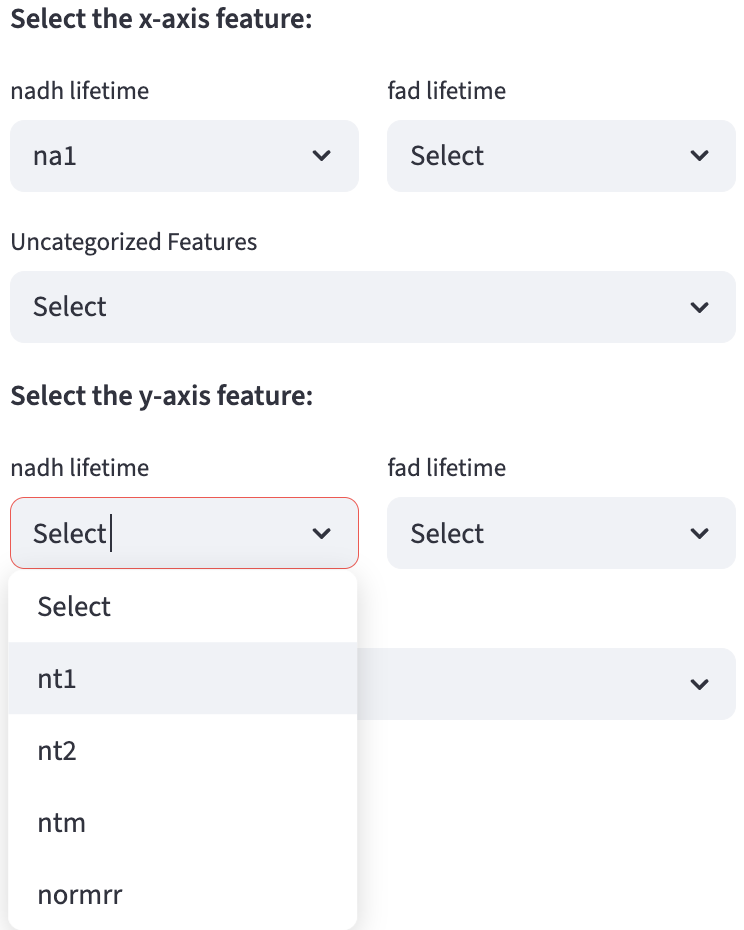
Bivariate Analysis
Two sets of selection widgets are rendered to allow maximum flexibility (the two features can be from the same or different feature groups). Each set of selection widgets behaves like the selection widgets in the univariate analysis. The first selected feature will be hidden in the second set of selection widgets.
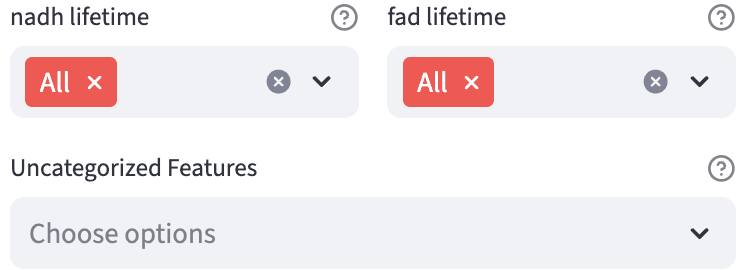
Multivariate Analysis
One set of selection widgets, each can select multiple features from a feature group, is rendered. A special value All is introduced so that users can conveniently select all features under the feature group. If users select All, all the other options will be cleared, and vice versa.
11.4.2 Filter Widgets
Categorical Filters

For complex datasets that are collected over multiple days, experiments, treatments, etc., it is useful to filter the data to focus on a subset of the data (data of interest). One filter widget is rendered for each categorical feature so that users have the flexibility to filter the data based on combinations of categorical features. All is a special option that include all categories of the selected categorical feature. Once it is selected, all the other options are cleared, and vice versa.
Numerical Filters
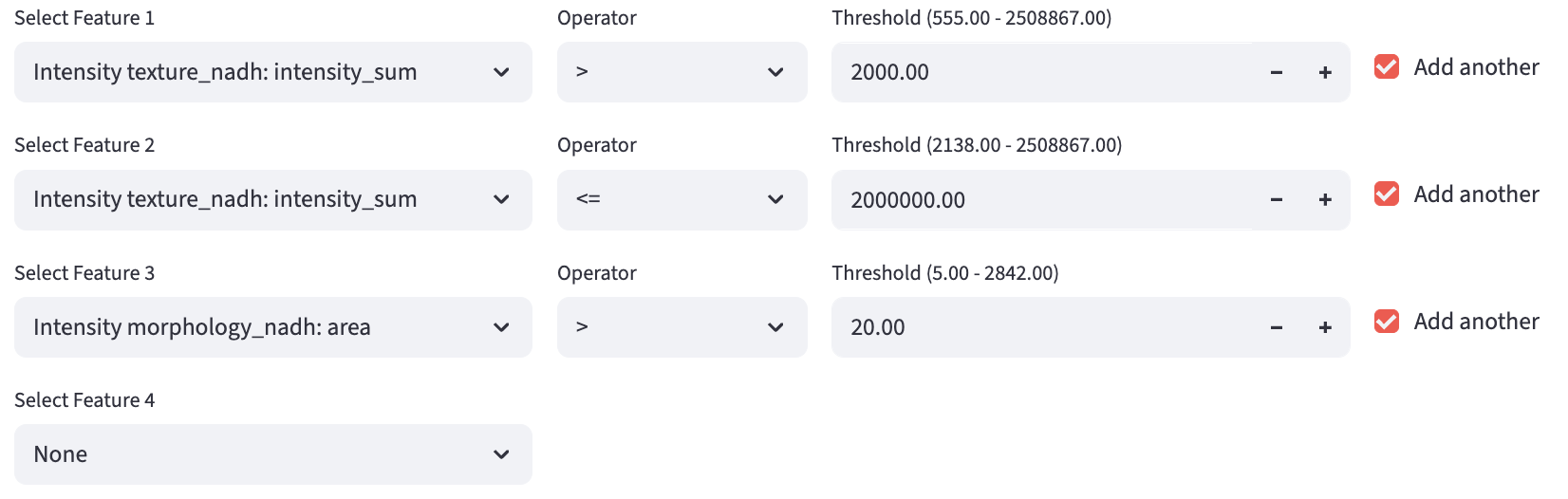
Users can further filter the data based on numerical features. Each row specifies a condition to filter the data:
Feature: the numerical feature to filter onOperator:>or<=Threshold: the range of values to filter on, dynamically updated based on previous filters, is displayed for reference. The entered value should be within the range.Add Another: add a new condition in the next row.
After the two sets of filters are applied, the final filtered data is used for visualization and analysis.
Make sure you clearly state all numerical filters used.
11.4.3 Visual Channels Widgets

Human vision is wired for rapid, parallel pattern and trend detection; good visual encodings (how to map data to visual elements such as color, shape, opacity, etc.) harness this to surface insights that raw numbers or text obscure1. FLIM Playground provides color, opacity, and shape channels for visualizations that support them:
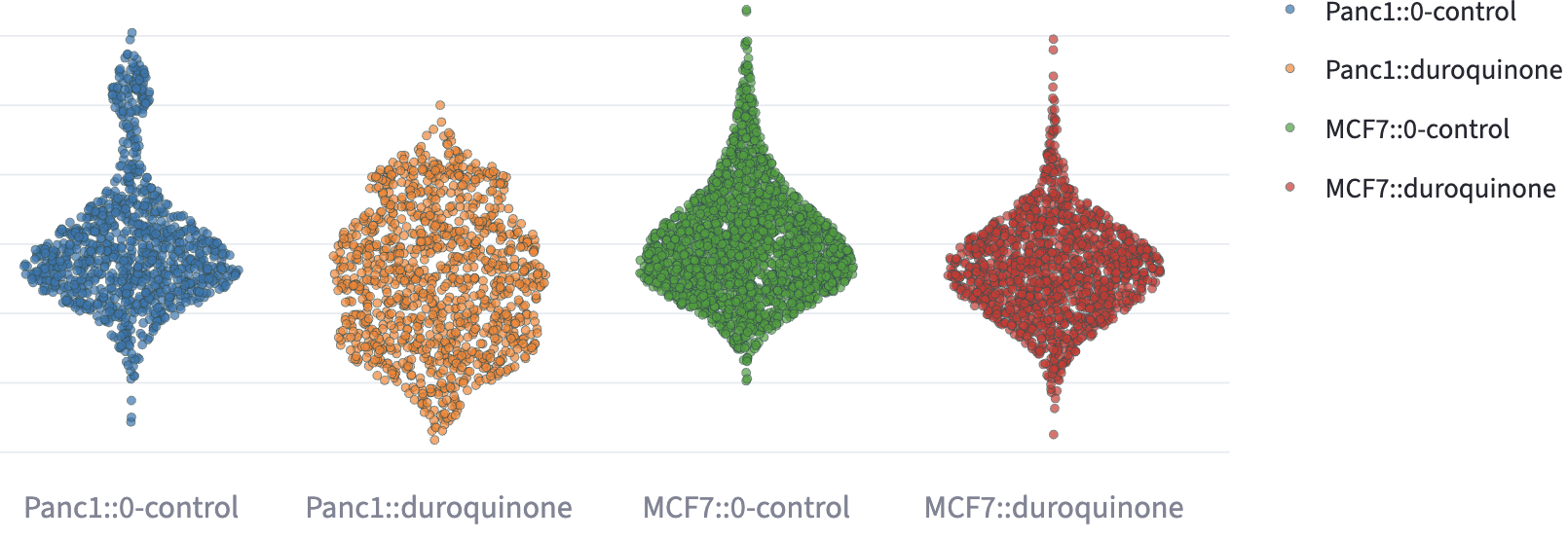
Color by
Color is supported in all methods except for Classification. In Color by, users can select multiple categorical features, and each unique combination of available categories in selected features is assigned a distinct color. Groups created by Color by show up in the x-axis (if multiple features, categories from each feature are delimited by ::).
The order of the groups in x-axis and in the legend is determined by:
the order of the selected features: categories of the first feature appear before those of the second, and so on and so forth. For example, the two treatments of
Panc1are together, because it is sorted first on the cell lines, then on treatments. If you want the treatments to be together, inColor byyou can selecttreatmentthencell_line.Numeric-alphabetical sort: within each feature, the category order is determined by the number inside (e.g.
1inPanc1) first, then the alphabetical order of the category name. Therefore, althoughPis afterMalphabetically, the1is before7numerically, makingPanc1appear beforeMCF7. This may be helpful when you have data from different days or hours. The default string sort will putDay 100beforeDay 30, and this is not what we want.
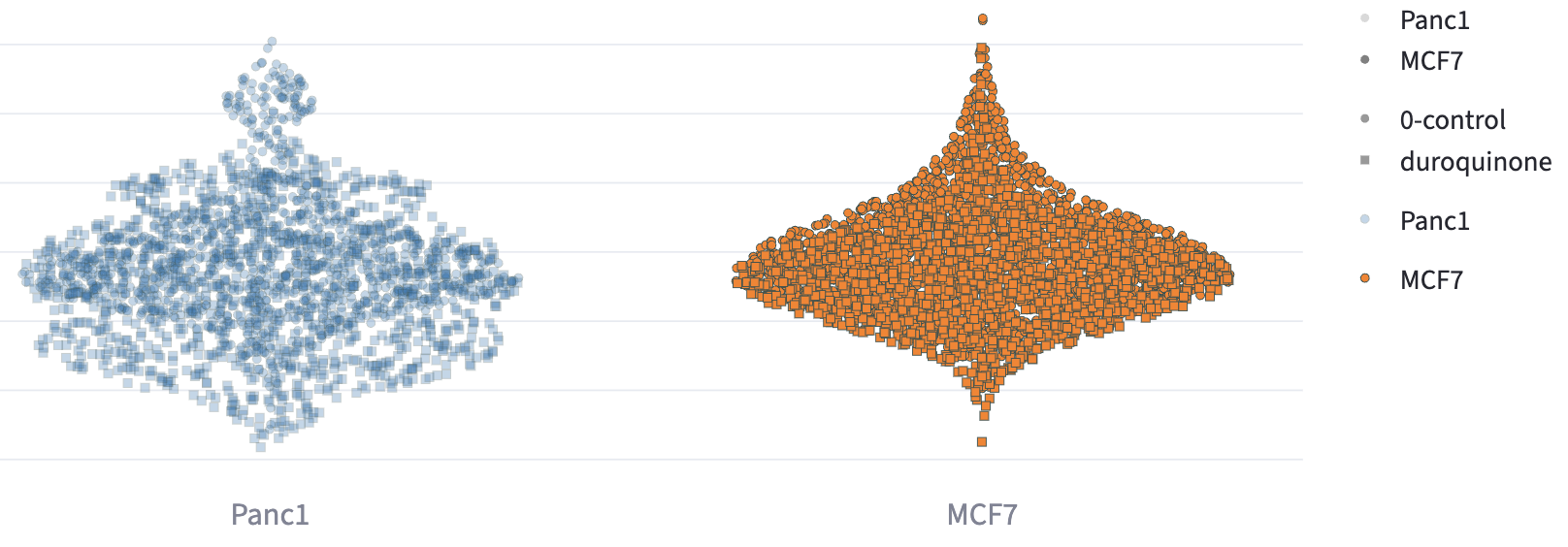
Opacity and Shape by
Opacity and shape are supported in all point-based visualizations (e.g. Feature Comparison, 2D Feature Distribution, Phasor Analysis, Dimension Reduction). In Opacity by and Shape by, users can select one categorical feature, and each unique category is assigned a distinct opacity or shape. The order of the shape and opacity is also sorted numeric-alphabetically.
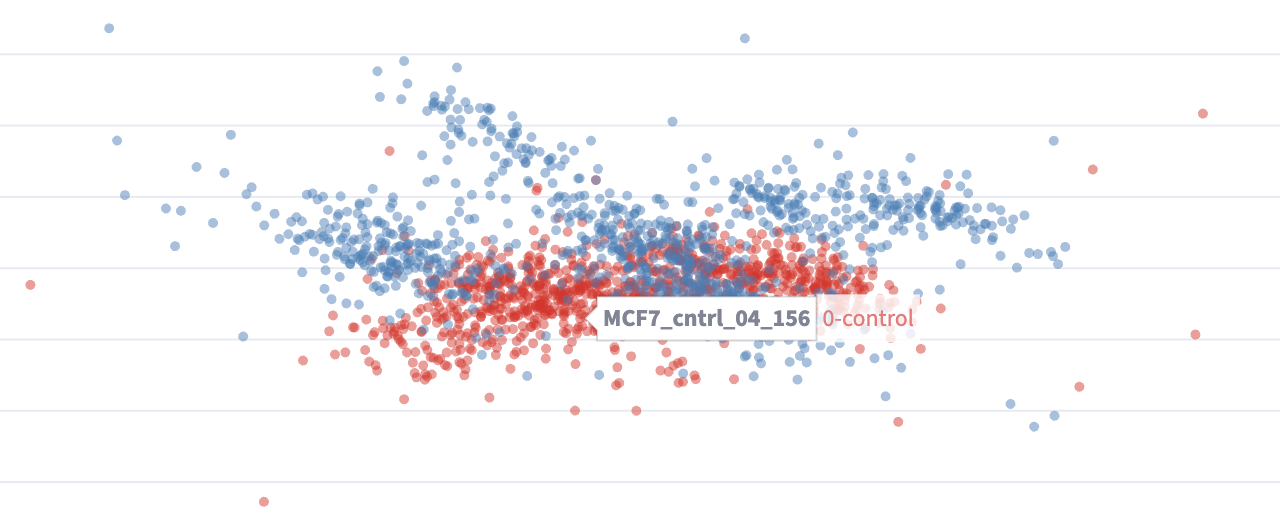
11.4.4 Unique ID Hover
- In all point-based visualizations, when hovering over a point, the unique id of the point will be shown.
11.4.5 Plotting Configuration Widgets

Users can interactively configure the following plot parameters:
- point size (if point-based)
- axis label size
- legend size
- the colormap used to color different groups
colorblind,tab10,tab20,Set1,Set2,Set3,Pastel1,Pastel2,Accent,viridis,plasma,inferno,magma,cividis
11.4.6 Export Workflow as Python Script
At the bottom right of the interface, users can export the entire analysis workflow as a self-contained Python script. This is useful when users want to share their analysis with others, reproduce their analysis later, customize the analysis further, or integrate it into their own workflow. The script will include all the code and analysis configuration (filters, selected numerical features, visual channels, plotting style, module-specific configurations, etc.). After exporting, users need to put the dataset in the same directory as the script and run the script to reproduce the analysis, where the plots are rendered as matplotlib figures and saved as SVG files for publication-ready quality.